
رباتها و سیستمهای هوش مصنوعی هنوز با محدودیتهای بزرگی روبرو هستند؛ آنها نمیتوانند مانند انسانها در محیط دنیای واقعی که پر از عدم قطعیت است، سریع و هوشمندانه تصمیم بگیرند. سیستمها و رباتهای مبتنی بر پردازشهای دیجیتال برای اینکه بتوانند در لحظه تصمیم درستی بگیرند باید میلیونها محاسبه تصادفی انجام دهند که اغلب به زمان، انرژی و هزینه بالایی نیاز دارد. رایانه ترمودینامیکی (Thermodynamic Computers) یا تراشه ترمودینامیکی مبتنی بر نوعی معماری محاسباتی است که بهجای تکیه بر منطق دیجیتال و پردازش باینری، از قوانین فیزیکی و رفتار طبیعی ذرات مانند نوسانها و نویزهای حرارتی برای انجام محاسبات استفاده میکند. در واقع، این رایانهها بهجای شبیهسازی تصادف و احتمال در نرمافزار، آن را مستقیماً در خود ماده و فیزیک سختافزار اجرا میکنند. درنتیجه، سیستم میتواند سریعتر، با مصرف انرژی کمتر و طبیعیتر مانند مغز انسان بیاموزد و تصمیم بگیرد. اگر علاقهمند هستید بدانید رایانه ترمودینامیکی چیست، نحوه عملکرد آن چگونه است و چطور هوش مصنوعی را به هوش طبیعی نزدیکترمیکند، پیشنهاد میکنم با این مطلب جذاب از میهن بلاکچین همراه باشید.
نقش سختافزار در پیشرفت هوش مصنوعی

در دنیای محاسبات، پیشرفتهای بزرگ همیشه حاصل برنامهریزیهای دقیق و ازپیشتعیینشده نبودهاند؛ بلکه گاهی الگوریتمها و فناوریهای نرمافزاری جدید بهطور غیرمنتظره با سختافزار موجود سازگار از آب درآمدهاند.
در اواخر دهه ۲۰۰۰، گروهی از پژوهشگران به رهبری جفری هینتون (Geoffrey Hinton) روی شبکههای عصبی کار میکردند؛ اما محاسبات سنگین ریاضی سد راهشان شده بود. آنها روزی، تصادفاً فهمیدند کارتهای گرافیکی (GPU) که در اصل برای اجرای بازیهای ویدئویی طراحی شدهاند، عملکرد شگفتانگیزی در انجام محاسبات ماتریسی عظیم دارند. این موضوع به پژوهشگران در آموزش مدلهای یادگیری عمیق در مقیاسهای بزرگ کمک کرد.
در سال ۲۰۱۷ نیز با معرفی معماری جدیدی به نام ترنسفورمر (Transformer) اتفاق مشابهی تکرار شد. این معماری که بر ضرب ماتریسهای بزرگ و منظم تکیه دارد، بهطور کامل با هسته تنسور کارتهای گرافیک همخوانی داشت. در نتیجه، محدودیتهای پردازش متوالی دادهها رفع شد و ترنسفورمرها توانستند با استفاده از کارتهای گرافیک موجود در بازار بهراحتی و با سرعت بالا آموزش ببینند.
وقعیت این است که انتخاب ترنسفورمرها در دنیای هوش مصنوعی بهخاطر این نیست که معماری کارآمدتری دارند؛ بلکه دلیل انتخاب آنها سازگاری تصادفیشان با سختافزارهای موجود است. این تطابق تصادفی، آغازگر عصر طلایی GPUها شد و رشد میلیارد دلاری صنعت هوش مصنوعی را رقم زد.
اما حالا که بشر میداند هوش مصنوعی دیگر یک داستان علمی تخیلی نیست و بهواقعیت پیوسته است، زمان آن است که نسل جدیدی از رایانهها را طراحی کنیم تا از اساس برای هوش مصنوعی ساخته شوند، نه برحسب تصادف.
رایانه دیجیتال چیست؟
رایانههای دیجیتال امروزی بر پایه منطق بولی (Boolean logic) ساخته شدهاند. یعنی هر چیزی در آنها یا «صفر» است یا «یک». درون این رایانهها میلیونها ترانزیستور وجود دارد که مانند کلیدهای کوچک، بین دو حالت روشن و خاموش جابهجا میشوند. اما نکته مهم این است که ترانزیستورها ذاتاً نویزدار هستند.
در علم فیزیک، اتمها و الکترونها همیشه در حال لرزش هستند؛ هرچه دما بالاتر رود، این لرزشها شدیدتر میشود. همین لرزشها باعث میشود گاهی الکترونها بهصورت تصادفی در مدار حرکت کنند یا جهت جریان را اندکی تغییر دهند. بنابراین، اگر بخواهیم سیگنال کاملاً پاکی (مثلاً یک عدد صفر یا یک) از ترانزیستور بگیریم، دمای محیط باعث مقدار اندکی بینظمی میشود و این یعنی همیشه احتمال خطا وجود دارد.
از دههها پیش، مهندسان تمام تلاش خود را کردهاند تا این بینظمی یا همان «نویز» را حذف کنند تا رایانهها بتوانند کاملاً قطعی (Deterministic) عمل کنند. آنها برای تحقق این هدف از روشهای مختلفی مانند استفاده از ولتاژ بالا برای غلبه بر نویز حرارتی، افزودن سامانههای تصحیح خطا برای جلوگیری از برعکس شدن بیتها و خنکسازی سختافزار برای کاهش لرزش اتمی و حذف نویز حرارتی کمک گرفتهاند. درنتیجه این تلاشها رایانههایی ساخته شده است که در آنها هر محاسبه دقیقا تکرارپذیر است؛ یعنی ورودی یکسان همیشه به همان خروجی میانجامد. به عبارت دیگر، رایانههای دیجیتال بر پایه حذف احتمال و تصادف طراحی شدهاند تا بتوانند محاسبات قطعی و منطق دودویی را اجرا کنند.
اما در طرف مقابل، دنیای هوش مصنوعیِ مولد (Generative AI) ذاتا بر پایه احتمال و تصادفیبودن بنا شده است. مدلهای انتشاری مانند استیبل دیفیوژن (Stable Diffusion) در هر مرحله از تولید بهصورت تصادفی نمونهبرداری میکند تا خروجی طبیعیتر شود. مدلهای مبتنی بر استنباط بیزی (Bayesian inference) برای تخمین عدم قطعیت، هزاران بار نمونهبرداری انجام میدهند. مدلهای مبتنی بر انرژی، در طول آموزش به فرآیندهای تکرارشونده تصادفی نیاز دارند و سیستمهای استنتاج فعال (Active Inference) مدام باورهای احتمالی خود را بهروز رسانی میکنند. اینها نشان میدهد که هوش مصنوعی برخلاف رایانههای دیجیتال بهنوعی «بینظمی کنترلشده» نیاز دارد تا بتواند خلاق، سازگار و واقعگرایانه عمل کند.
اینجا دقیقاً همان پارادوکس بزرگ در دنیای محاسبات شکل میگیرد؛ ما الگوریتمهایی که بر پایه تصادف طراحیشدهاند را روی همان ماشینهای قطعی اجرا میکنیم که سالها تلاش کردهایم هیچ تصادف و نویزی در آنها نباشد. درواقع، ابتدا انرژی و پیچیدگی عظیمی را صرف طراحی تراشهها میکنیم که نویز را در سطح سختافزار سرکوب کند و ماشین دیجیتال پایدار بماند. بعد دوباره انرژی بیشتری میسوزانیم تا همان تصادفیبودن را از طریق شبیهسازی نرمافزاری به سیستم بازگردانیم. بههمین دلیل، معماری محاسباتی امروز با ماهیت الگوریتمهایی که میخواهیم اجرا کنیم، ناهماهنگ است.
نتیجه این ناهماهنگی همان چیزی است که امروز میبینیم؛ خوشههای عظیم GPU برای اجرای مدلهای هوش مصنوعی، به اندازه یک شهر برق مصرف میکنند. اگر همین روند ادامه پیدا کند، مصرف انرژی مراکز داده بهقدری بالا میرود که زمین دیگر قادر به دفع گرمای آن نخواهد بود. این وضعیت از دیدگاه عصبشناسی و زیستشناسی انسان یک پارادوکس مضحک بهنظر میرسد. رویکرد کنونی نسبت به هوش مصنوعی ما را واداشته تا برای تغذیه ذهنهای مصنوعی، انرژی یک «خورشید مینیاتوری» را بسازیم و مهار کنیم؛ در حالیکه مغز انسان با تنها یک موز و یک لیوان آب در روز، عملکرد مشابهی را ارائه میدهد.
همین شکاف میان تقاضا و عملکرد محاسباتی را میتوانیم یک فرصت بزرگ ببینیم. اکنون زمان آن رسیده است تا مسیر را عوض کنیم و بهجای اجرای الگوریتمهای احتمالی روی ماشینهای قطعی، تراشههایی بسازیم که ذاتاً بر پایه احتمال و تصادف باشند. چنین تراشههایی میتوانند الگوریتمهای هوش مصنوعی را بهصورت طبیعی و با مصرف انرژی کمتر اجرا کنند.
رایانه ترمودینامیکی چیست؟

همانطور که متوجه شدیم، مهندسان علوم رایانه تا امروز تمام تلاش خود را کردهاند تا نویز حرارتی (حرکت تصادفی ذرات در اثر گرما) را در رایانههای دیجیتال از بین ببرند. اما در رایانههای ترمودینامیکی (Thermodynamic Computers) داستان برعکس است؛ این دستگاهها به جای سرکوب نویز، از آن بهعنوان منبع انرژی محاسباتی استفاده میکنند.
یک رایانه ترمودینامیکی میتواند با استفاده از نوسان طبیعی دما و انرژی درون ماده، نقش یک منبع تولید تصادف هدفمند را ایفا کند. اگرچه این نوسانها، تصادفی بهنظر میرسند؛ اما درواقع یک ساختار آماری و قابلپیشبینی دارند که براساس دما تغییر میکند. رایانه ترمودینامیکی میتواند این ساختار را شکل دهد و هدایت کند تا دقیقاً همان نوع «تصادف مفید» ایجاد شود که برای حل مسائل پیچیده هوش مصنوعی لازم است.
رایانههای ترمودینامیکی را میتوان شبیه به یک تولیدکننده اعداد تصادفی قابلبرنامهریزی دانست. در رایانههای معمولی، برای اینکه بخواهیم از یک توزیع خاص (مثلاً توزیع نرمال یا گاوسی) عدد تصادفی تولید کنیم، باید هزاران محاسبه انجام دهیم. اما در رایانه ترمودینامیکی کافی است به آن بگوییم از چه نوع توزیعی میخواهیم نمونه بگیرد؛ سپس خود دستگاه، مستقیماً از همان توزیع عدد تولید میکند. به این ترتیب، دیگر نیازی به آن همه محاسبات پیچیده ریاضی نیست.
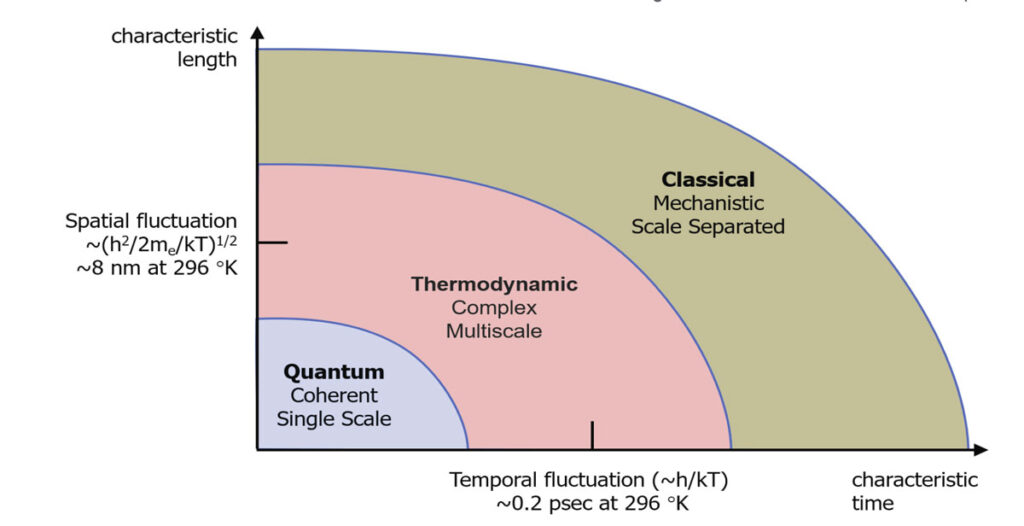
در این مدل، خودِ فیزیک به نمونهگیر (sampler) تبدیل میشود. بهجای آنکه رایانه، حرکات تصادفی را با نرمافزار شبیهسازی کند که بسیار پرهزینه و زمانبر است؛ سختافزار مستقیما همان دینامیک را در سطح فیزیکی پیاده میکند. بهبیان دیگر، در سختافزار ترمودینامیکی، چشمانداز انرژی (Energy landscape) مسئله در ساختار تراشه تعبیه میشود و وضعیت سیستم تحت نیروهای فیزیکی واقعی و نویز حرارتی تغییر میکند تا به حالت تعادل (Equilibrium) برسد. درنتیجه، خود دستگاه به طور طبیعی از قوانین فیزیک پیروی میکند و از دل آن، نمونهگیری انجام میدهد.
به این ترتیب، در رایانههای ترمودینامیکی دیگر با «محاسبات الهامگرفته از فیزیک» روبرو نیستیم؛ بلکه خودِ فیزیک در حال محاسبه است. این همان جایی است که محاسبه به یک پدیده طبیعی تبدیل میشود و میتوانیم آن را نزدیکترین شکل به «هوش طبیعی» بدانیم.
اما چرا این موضوع تا این اندازه مهم است؟ رایانههای ترمودینامیکی یکی از پرهزینهترین مراحل هوش مصنوعی احتمالاتی (Probabilistic AI) را تسریع میکند و امکان تولید نمونههایی از توزیعهای احتمال پیچیده را فراهم میکند. بسیاری از الگوریتمها مانند استنتاج زنجیره مارکوف مونت کارلو (MCMC) مدلهای مولد مبتنی بر انتشار و یادگیری مبتنی بر انرژی همگی بر پایه افزودن مکرر نویز و رهاسازی بهسمت تعادل کار میکنند.
برای اینکه چنین الگوریتمهایی درست کار کنند، باید میلیاردها بار نمونه تصادفی تولید شود و گرادیانهایی که یادگیری را ممکن میسازند، محاسبه شوند تا از گیرافتادن سیستم در راهحلهای غیربهینه جلوگیری شود.
در رایانههای دیجیتال، تمام این فرآیندها با اعداد شبهتصادفی شبیهسازیشده و میلیونها عملیات ریاضی انجام میشود که یک فرایند بسیار کند، پرهزینه و انرژیبر است. در مقابل، در یک رایانه ترمودینامیکی این عملیات در بافت خود سختافزار اتفاق میافتد. نیروی «گرادیان نزولی» که در یادگیری ماشین نقش کلیدی دارد، در اینجا به نیروی فیزیکی واقعی تبدیل میشود که بر سیستم اثر میگذارد. نویز تصادفی هم دیگر شبیهسازی نمیشود؛ بلکه بهطور طبیعی از نویز حرارتی ذاتی دستگاه پدید میآید.
بهجای اینکه معادلات پیچیده دیفرانسیل تصادفی را در نرمافزار حل کنیم، سختافزار ترمودینامیکی آنها را در قالب فرآیندهای طبیعی اجرا میکند. این یعنی، نمونهگیری، رسیدن به تعادل و همگرایی، همگی بهصورت طبیعی رخ میدهد، نه در قالب شبیهسازی مصنوعی.
نتیجه این رویکرد حیرتانگیز است؛ زیرا سرعت و بهرهوری انرژی در یادگیری، استنتاج و تولید مدلهای هوش مصنوعی هزاران برابر افزایش مییابد. از این رو، رایانههای ترمودینامیکی را میتوان هسته محاسباتی نسل آینده هوش مصنوعی دانست.
ادعاهای مربوط به عملکرد فوقالعاده رایانههای ترمودینامیکی در آزمایشهای تجربی نیز تایید شده است:
- بهرهوری انرژی: رایانههای ترمودینامیکی از نظر مصرف انرژی نسبت به رایانههای دیجیتال کارآمدتر هستند. نتایج یک پژوهش در سال ۲۰۲۵ نشان میدهد که این رایانهها در انجام محاسبات مربوط به بهینهسازی گرافها تا ۹٬۷۱۲ برابر انرژی کمتری نسبت به دستگاههای کلاسیک استفاده میکنند و حتی با رایانههای کوانتومی تبریدی (Quantum annealers) قابلمقایسه هستند.
در شبیهسازیهای الکترونیکی انجامشده روی تراشههای ۲۸ نانومتری نیز مصرف انرژی برای عملیات نمونهگیری، ۱ میلیون برابر کمتر از روشهای دیجیتال گزارش شده است. - سرعت: سرعت رایانههای ترمودینامیکی نیز حیرتانگیز است. پژوهشها نشان دادهاند که انجام عملیات نمونهگیری زنجیره مارکوف در این سیستمها حدود ۵۰۰ برابر سریعتر از پیادهسازی نرمافزاری است. حتی نمونههای اولیه ساختهشده روی مدار یکپارچه دیجیتال برنامهپذیر (FPGA) توانستهاند در هر ثانیه ۵۰ تا ۶۴ میلیارد تغییر حالت انجام دهند. این سرعت به آنها اجازه میدهد تا فرآیندهای یادگیری پیچیدهای مانند واگرایی تقابلی “Contrastive Divergence” را با ۱۰۰ هزار بار نمونهگیری متوالی انجام دهند؛ کاری که در سختافزارهای فعلی تقریبا غیرممکن است.
- کاربردهای واقعی: تراشههای ترمودینامیکی در مقایسه با فناوریهای پیشرفته هم کارآمدتر هستند. بهطور مثال، در آزمون معروف دستهبندی ارقام دستنویس (MNIST) ماشینهای بولتزمن پراکنده (SBM) با تنها ۳۰٬۰۰۰ پارامتر به ۹۰٪ دقت رسیدند؛ درحالیکه مدلهای مشابه در رایانههای معمولی برای رسیدن به همان دقت، به ۳.۲۵ میلیون پارامتر نیاز داشتند. این یعنی سیستم با ۱۰۰ برابر پارامتر کمتر، همان دقت را به دست آورده است و نشان میدهد که محدودیتهای سختافزاری هم مانعی عملکرد بالا نمیشوند.
پلتفرمهای رباتیک احتمالی و استنتاج فعال؛ اختراع رباتهایی که فقط محاسبه نمیکنند، بلکه میفهمند
در حالحاضر، شرکت نومنال لبز (Noumenal Labs) پیشگام مرحله جدیدی از هوش مصنوعی است و چارچوبی را برای ایجاد هوش مصنوعی تجسمیافته (Embodied intelligence) در دنیای فیزیکی پویا و پر از عدم قطعیت طراحی کرده است. رباتهایی که روی زمینهای ناهموار حرکت میکنند، بازوهای رباتیکی که اجسام شکننده را جابهجا میکنند یا پهپادهایی که در آسمان تصمیمهای لحظهای میگیرند، همه در محیطهایی فعالیت دارند که هیچ چیز قطعی نیست. در چنین شرایطی، یک اشتباه کوچک ممکن است، پیامدهای مادی سنگینی داشته باشد یا حتی به یک فاجعه واقعی منجر شود.
هوش مصنوعی امروزی هنوز چنین درکی ندارد. شبکههای عصبی عمیق، یک پیشبینی تکنقطهای ارائه میدهد، بدون اینکه بدانند تا چه حد به آن پاسخ اطمینان دارند. این سیستمها نمیتوانند میزان ناآگاهی خود را تشخیص دهند و در نتیجه، نمیدانند چه زمانی باید محتاطتر عمل کنند. این تفاوت اصلی آنها با انسانها است.
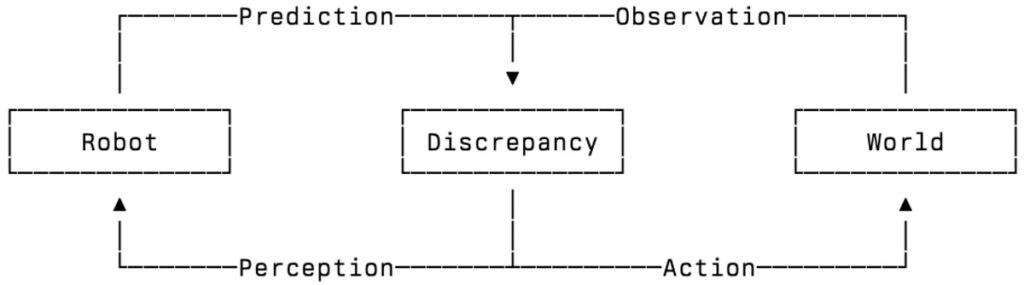
برای اینکه رباتها در دنیای واقعی کاربرد داشته باشند، باید از استنباط احتمالاتی (Probabilistic Inference) استفاده کنند. این نوع استنباط معمولا با استفاده از روشهایی مانند فیلتر ذرات (Particle Filtering)، انتشار باور (Belief Propagation) و مدلهای مبتنی بر درک واقعی از جهان (Grounded World Models) تصمیمگیری در شرایط عدمقطعیت را ممکن میسازد. اجرای درست این روشها نیازمند دانش و تخصصی است که در چارچوبی به نام استنباط فعال (Active Inference) آموزش داده میشود و از کارکرد مغز انسان الهام گرفته است.
در استنباط فعال، دو فرایند اصلی یعنی ادراک (Perception) و کنترل (Control) از هم جدا نیستند. در این مدل، ربات بهطور مداوم باورهای خود درباره جهان را بهروزرسانی میکند و اقداماتی انجام میدهد که «انرژی آزاد مورد انتظار» را کاهش میدهد؛ بهعبارت سادهتر، ربات با هر حرکت یا ادراک جدید، تلاش میکند به شناخت واقعیتری از محیط برسد و خطای پیشبینی خود را کمتر کند. این همان سازوکاری است که مغز انسان برای یادگیری و تصمیمگیری بهکار میگیرد.
مشکل اصلی اینجاست که رویکردهای مبتنی بر استنباط بیزی مانند استنباط فعال از نظر محاسباتی بسیار سنگین هستند. بخش عمدهای از توان پردازشی آنها (حدود ۹۰٪ از رانتایم) صرف انجام نمونهگیریهای تصادفی میشود. بههمین دلیل اجرای این روشها در سیستمهای کوچک یا رباتهای متحرک فعلا دشوار و غیرممکن است.
رایانههای ترمودینامیکی این مانع بزرگ را از بین میبرند و راه را برای استفاده از هوش مصنوعی در دستگاههای واقعی مانند رباتها باز میکنند. در چارچوب استنتاج فعال، هر بهروزرسانی ادراکی یا حرکتی نیازمند نمونهگیری تصادفی از توزیعهای احتمالی (از نمونهگیری پسین گرفته تا انتخاب سیاست حرکت) است. رایانههای ترمودینامیکی دقیقاً همین کار را بهطور طبیعی انجام میدهند. نمونهگیری پسین (posterior sampling) متناظر با تعادل طبیعی شبکههای p-bit است که توزیعهای احتمالی را رمزگذاری میکنند، در حالیکه انتخاب سیاست (policy exploration) از همان نوسانهای حرارتی ناشی میشود که سختافزار را هدایت میکند. آنچه پردازندههای دیجیتال از طریق چرخههای فوقالعاده پرهزینه تولید تصادفی شبیهسازی میکنند، در سامانههای ترمودینامیکی بهصورت ذاتی تحقق مییابد.
با تبدیل نمونهبرداری از یک الگوریتم به یک فرآیند فیزیکی، امکان اجرای استنتاج فعال در زمان واقعی با مصرف انرژی بسیار پایین فراهم میشود. این فناوری پایهگذار نسل جدیدی از رباتها و سیستمهای هوشمند است که با آگاهی از عدم قطعیت و سازگاری بالا در دنیای واقعی عمل میکنند.
جمعبندی
یکی از مهمترین موانع پیشرفت رباتها و ایجنتهای هوش مصنوعی، چالش نمونهگیری در استنتاج فعال است. هر بار که یک ربات میخواهد باور خود را بهروزرسانی کند یا تصمیمی بگیرد، باید هزاران بار نمونهگیری تصادفی انجام دهد. این کار برای رباتهایی که باید در لحظه تصمیم بگیرند، عملاً هزینهبر و بسیار کند است. رایانههای ترمودینامیکی نویدبخش نسل جدیدی از هوش فیزیکی هستند و میخواهند این مانع را با استفاده از خود فیزیک برطرف کنند. در این مدل، نویزهای حرارتی و نیروهای طبیعی به ابزارهایی برای پردازش اطلاعات و تصمیمگیری تبدیل میشوند و بهجای شبیهسازی نرمافزاری، نمونهگیری و بهروزرسانی باورها بهصورت طبیعی انجام میشود.
رایانههای ترمودینامیکی پاسخی برای این پرسش قدیمی هستند که «چرا مغز به جای چند گیگاوات انرژی میتواند تنها با یک فنجان قهوه تمام محاسبات خود را انجام دهد؟»












