
رندوم فارست (Random Forest) یا جنگل تصادفی یکی از الگوریتمهای پرکاربرد یادگیری ماشین (Machine Learning) است. این الگوریتم که توسط دو متخصص علم آمار یعنی لئو برایمن (Leo Breiman) و ادل کاتلر (Adele Cutler) ابداع شده است، خروجی چندین درخت تصمیم (Decision Tree) را برای رسیدن به یک نتیجه واحد، ترکیب میکند. جنگل تصادفی با استقبال خوبی روبهرو شده است؛ زیرا علاوه بر سهولت در استفاده و انعطافپذیری، مشکل گروهبندی و رگرسیون را نیز توانسته حل کند. در ادامه به توضیح اینکه الگوریتم جنگل تصادفی چیست و چگونه در پیشبینی قیمت بیت کوین مورد استفاده قرار میگیرد، میپردازیم.
الگوریتم جنگل تصادفی چیست؟

از آنجایی که مدل جنگل تصادفی متشکل از چندین درخت تصمیم است، در ابتدا به توضیح مختصری درباره این مفهوم میپردازیم. درخت تصمیم همواره با یک سوال کلی مانند «آیا امروز برای موجسواری مناسب است؟» شروع میشود و در ادامه برای پیدا کردن پاسخ مناسب، سلسلهای از پرسشها مانند «آیا دریا موج دارد؟» یا «آیا باد موافق است یا مخالف؟» پرسیده میشود. این سوالات گرهها یا نودهای تصمیمگیری درخت تصمیم را تشکیل میدهند و وسیلهای برای تقسیم دادهها هستند. لازم بهذکر است منظور از نود، نودهای ساختمان داده است و ارتباطی با نودهای شبکههای بلاک چینی ندارد. هر سوال به فرد کمک میکند که به تصمیم نهایی برسد که با نود برگ مشخص شدهاند. عمدتا پاسخ این پرسشها به دو صورت بله یا خیر داده میشوند. مشاهداتی که با معیارها مطابق دارند از شاخه «بله» و مشاهداتی که با معیارها تطابق ندارند، مسیر جایگزین را دنبال خواهند کرد.
درختهای تصمیم بهدنبال یافتن بهترین تقسیم برای زیرمجموعه دادهها هستند و معمولا از طریق الگوریتم “درخت گروهبندی و رگرسیون (Classification and Regression Tree)” این کار را انجام میدهند. کیفیت تقسیمبندی انجام شده از طریق بهکارگیری روشهایی مانند جینی ناخالص، افزایش اطلاعات یا خطای میانگین مربعات اندازهگیری میشود.
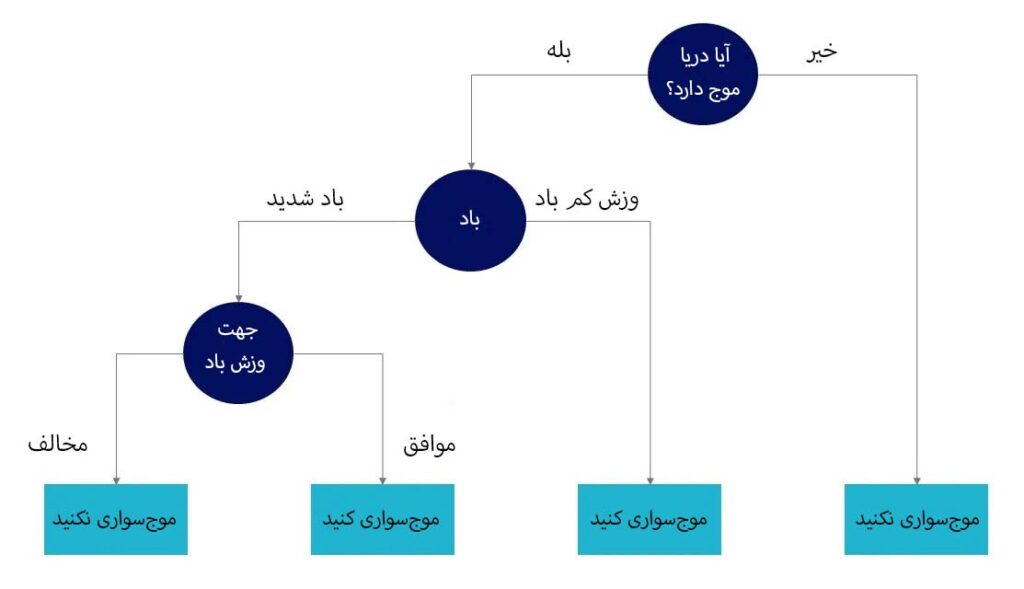
این درخت تصمیم، مثالی برای مساله گروهبندی است که گروهها تحت عنوان «موجسواری کنید» و «موج سواری نکنید» جدا میشوند.
درختهای تصمیم میتوانند مستعد مشکلاتی مانند خطای شناختی و برازش بیش از حد باشند. با این حال، زمانی که چندین درخت تصمیم در گروههای مختلف (Ensemble)، الگوریتم جنگل تصادفی را تشکیل میدهند، نتایج دقیقتری پیشبینی میکنند؛ مخصوصا زمانی که هر کدام از درختان با یکدیگر همبستگی نداشته باشند.
روش گروهی (Ensemble Methods)
روشهای یادگیری گروهی از مجموعهای از روشهای طبقهبندیکننده مانند درختان تصمیم تشکیل شدهاند و پیشبینیهای آنها برای شناسایی محبوبترین نتیجه، تجمیع میشوند. شناختهشدهترین «روشهای گروهی» کیسه یا Bagging نام دارد.
در روش گروهی، یک نمونه تصادفی از دادهها در یک مجموعه با امکان جایگزینی انتخاب میشود. این به این معنی است که هرکدام از دادهها را میتوان بیش از یک بار انتخاب کرد. پس از ایجاد چندین نمونه داده، مدلها بهطور مستقل برآورد میشوند و باتوجه به نوع برآورد آنها، یعنی رگرسیون هستند یا طبقه بندیکننده، میانگین یا اکثریت آن پیشبینیها، دقیقتر تخمین میزنند. این رویکرد بهطور متداول برای کاهش واریانس در دادههای پراکنده مورد استفاده قرار میگیرد.
رندوم فارست چیست؟
الگوریتم جنگل تصادفی یا همان Random Forest یک مدل توسعهیافته از روش کیسه است؛ زیرا در این الگوریتم از هر دو روش کیسه و ویژگیهای تصادفی برای ایجاد یک جنگل بدون همبستگی از درختان تصمیم، استفاده میشود. ویژگیهای تصادفی بهعنوان ویژگی کیسه شناخته میشوند. این ویژگی، زیر مجموعههای تصادفی از ویژگیها میسازد که همبستگی کم را میان درختهای تصمیم، تضمین میکند. این یکی از تفاوتهای کلیدی میان درخت تصمیم و جنگلهای تصادفی است. درخت تصمیم تمام ویژگیهای تقسیمشده ممکن را در نظر میگیرد، در حالی که جنگل تصادفی تنها زیرمجموعهای از آن ویژگیها را انتخاب میکند.
اگر به مثالی که قبلتر زدیم یعنی «موجسواری» برگردیم، ممکن است سوالاتی که فرد اول نسبت به فرد دوم میپرسد، کاملتر و جامعتر نباشد. با درنظر گرفتن تنوعهای احتمالی در دادههای جمعآوری شده، میتوانیم خطر برازش بیش از حد، خطای شناختی و واریانس کلی را کاهش دهیم و در نتیجه، پیشبینیهای دقیقتری انجام دهیم.
الگوریتم جنگل تصادفی چگونه کار میکند؟
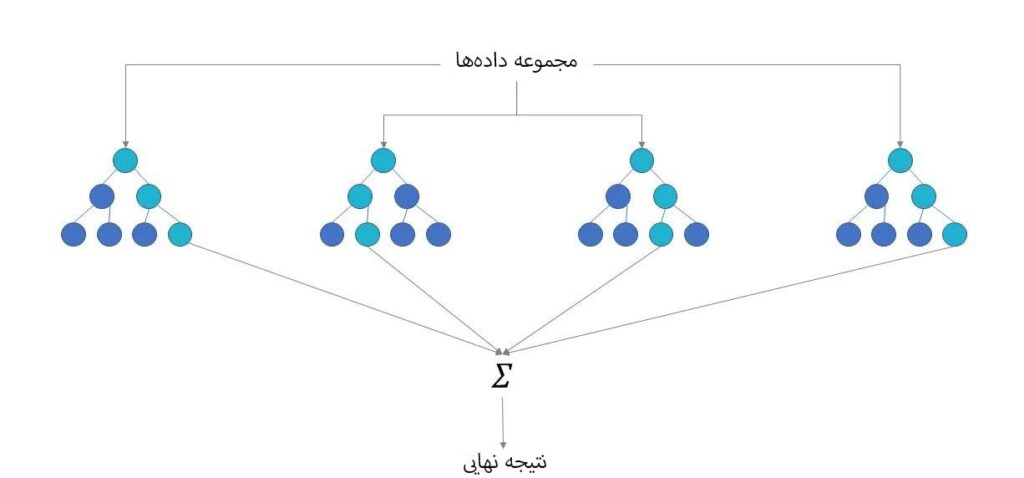
الگوریتم رندوم فارست دارای سه متغیر اصلی است که باید قبل از بهکارگیری، تنظیم شوند. این متغیرها شامل اندازه نودها، تعداد درختان و تعداد ویژگیهای نمونهبرداری شده میشود. طبقهبندی جنگل تصادفی می تواند برای حل مشکلات رگرسیونی یا گروهبندی مورد استفاده قرار گیرد.
الگوریتم جنگل تصادفی از چندین درخت تصمیم ساخته میشود. هر درخت در هر گروه، شامل نمونه دادههایی از یک مجموعه داده برآوردکننده ساخته شده است. یک سوم از مجموعه دادههای که در برآورد نمونه استفاده میشوند، بهعنوان دادههای آزمایشی کنار گذاشته میشوند و آنها را بهعنوان نمونههای خارج از کیسه یا Out of Bag میشناسند. برای اینکه تنوع بیشتری به مجموعه دادهها اضافه شود، از کیسه ویژگیها نمونههای تصادفی دیگری به فرآیند پیشبینی اضافه میشود. این کار منجر به کاهش همبستگی میان درختان تصمیم میشود.
با توجه به نوع مشکل، تعیین پیشبینی متفاوت خواهد بود. برای مواردی که به حالت رگرسیونی یا بازگشتی هستند، درختان تصمیم میانگینگیری میشوند و برای زمانی که قرار است روی مورد دستهبندی شده پیشبینی انجام شود، با توجه به رای اکثریت یعنی متداولترین متغیر گروهی، پیشبینی شکل می گیرد. در انتها نمونههای خارج از کیسه برای اعتبارسنجی و نهاییسازی پیشبینی مورد استفاده قرار خواهند گرفت.
مزایا و چالشهای Random Forest
استفاده از الگویتم جنگل تصادفی مزایا و چالشهایی به همراه دارد. در ادامه به بررسی هر کدام خواهیم پرداخت.
مزایای استفاده از الگوریتم جنگل تصادفی
کاهش ریسک برازش بیشازحد: درختان تصمیم در مدل خود سعی دارند تمام دادهها را بهصورت مناسب نمایش دهند و این ریسک برازش بیشاز حد را افزایش میدهند. هنگامی که تعداد زیادی درخت تصمیم، در یک جنگل تصادفی وجود داشته باشد، تا زمانی که میانگین درختان غیر مرتبط کمتر از واریانس کلی و خطای پیشبینی باشد، طبقهبندی انجام شده مدل را بیش از حد متناسب نشان نخواهد داد.
انعطافپذیری: از آنجایی که جنگل تصادفی میتواند برآوردهای رگرسیونی و طبقهبندی را با درجه بالایی از دقت انجام دهد، یک روش محبوب میان علاقهمندان به علوم داده است. ویژگی Bagging گروهبندی جنگل تصادفی را به ابزاری کارآمد برای تخمین مقادیر از دست رفته تبدیل میکند؛ زیرا در این صورت یعنی از دست رفتن بخشی از دادهها همچنان دقیق باقی میماند.
سهولت در تعیین اهمیت ویژگیها: الگوریتم جنگل تصادفی تشخیص اهمیت یا میزان سهم متغیرها را در الگو آسان میکند. راههای مختلفی برای این کار وجود دارد. معمولا جینی (Gini) و میانگین کاهش در ناخالصی (Mean Decrease in Impurity) برای اندازهگیری میزان کاهش دقت مدل در هنگام حذف یک متغیر استفاده میشود. یکی دیگر از معیارها برای مشخص کردن اهمیت ویژگیها، «جایگشت اهمیت» است که بهعنوان میانگین کاهش دقت (Mean Decrease Accuracy) نیز شناخته میشود. MDA میانگین کاهش دقت را به وسیله جایگشت تصادفی مقادیر ویژگیها، در نمونههای خارج از کیسه اندازهگیری میکند.
چالشهای استفاده از الگوریتم رندوم فارست
زمانبر بودن فرایند: از آنجایی که الگوریتم جنگل تصادفی میتواند مجموعهای از دادههای بزرگ را مدیریت کند، پیشبینیهای دقیقتری نیز ارائه میکند؛ اما بهدلیل محاسبه دادهها برای هر درخت تصمیمگیری، فرایند آهستهای محسوب میشود.
منابع زیادی نیاز دارد: از آنجایی که جنگل تصادفی مجموعه دادههای بزرگتری را پردازش میکنند، برای ذخیره این دادههای به منابع بیشتری نیاز دارد.
پیچیدگی: تفسیر پیشبینی یک درخت تصمیم آسانتر از تفسیر نتایج حاصل از یک جنگل مملو از درختهای پیشبینی است.
چگونه قیمت بیت کوین را بهوسیله الگوریتم جنگل تصادفی پیشبینی میکنند؟
الگوریتم جنگل تصادفی در حوزههای مختلفی مورد استفاده قرار میگیرد. برای اینکه بهصورت ملموستر نحوه کاربرد الگوریتم رندوم فارست را متوجه شویم، استفاده از این الگوریتم را برای پیشبینی قیمت بیت کوین مثال میزنیم.
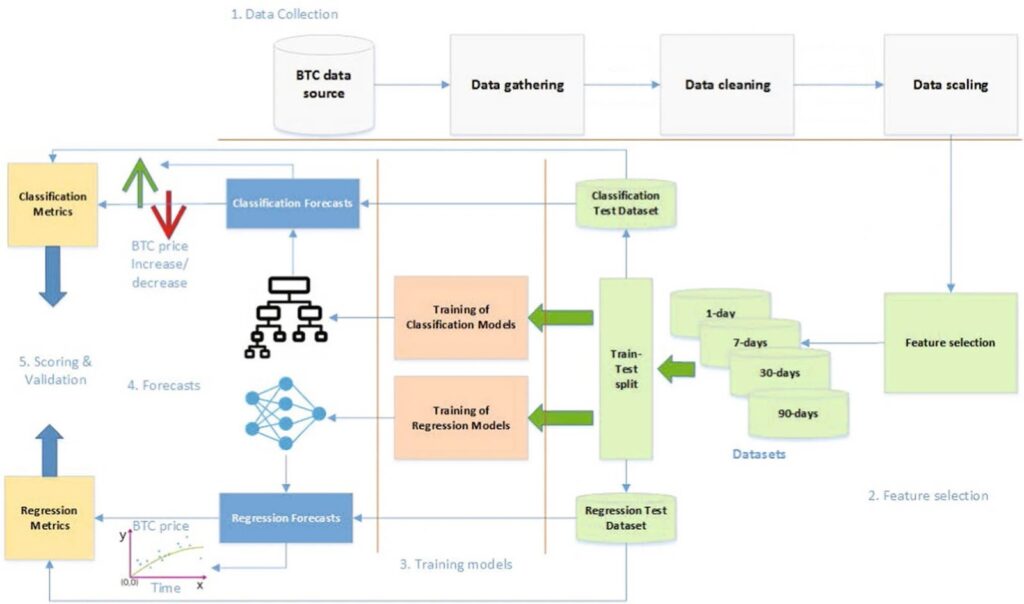
تصویر بالا روند کلی پیشبینی قیمت بیت کوین با استفاده از الگوریتم جنگل تصادفی را نشان میدهد. این روند شامل پنج بخش جمعآوری داده، انتخاب ویژگیها، برآورد مدلها، پیشبینی و نهایی سازی و ارائه نتیجه میشود.
در بخش اول که مربوط به جمعآوری داده میشود، باید متغیرهایی را که میخواهیم برای پیشبینی قیمت بیت کوین استفاده کنیم، انتخاب کنیم. این دادهها میتوانند قیمت شروع، قیمت پایانی، بیشترین قیمت، کمترین قیمت، حجم مبادلات یا هر متغیر دیگری که مربوط به قیمت بیت کوین میشود، باشد. بعد از جمعآوری و یک دست کردن دادهها، نوبت به هممقیاس کردن دادهها (Data Scaling) میشود. گروهی از دادهها بزرگ و گروهی بسیار کوچک هستند. با هممقیاس کردن دادهها، بازه اعداد در یک مقدار مشخص قرار خواهد گرفت.
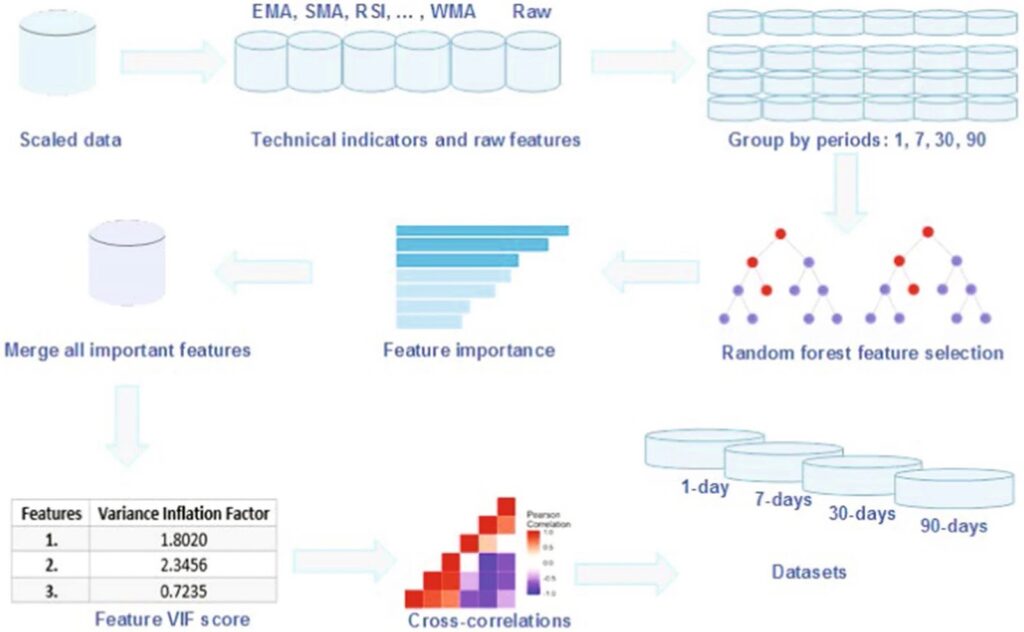
از مرحله Scaling به بعد، الگوریتم جنگل تصادفی وارد فرایند میشود و به دستهبندی دادهها میپردازد. همانطور که در تصویر بالا مشاهده میکنید، بعد از دادههای هممقیاسشده، باید ویژگیها و معیارهای اندازهگیری را که میخواهیم استفاده کنیم، معرفی کنیم.
بیش از ۴۰ اندیکاتور مانند شاخص جریان پول (MFI)، میانگین وزنی حجم قیمت (VWAP)، میانگین متحرک ساده (SMA)، ایچیموکو، شاخص قدرت نسبی (RSI) و غیره در تحلیل تکنیکال مورد استفاده قرار میگیرد. علاوهبر آن تایم فریمهای هر کدام از موارد نیز باید در نظر گرفته شود. بهعنوان مثال میتوان از تایم فریمهای روزانه، هفتگی، سی روزه و ۹۰ روزه استفاده کرد.
پس از اینکه دادهها بر اساس زمان گروهبندی شدند، الگوریتم جنگل تصادفی آغاز میشود. ویژگیها بر اساس اهمیت مرتب شده و بعد از ادغام (Merge)، براساس آزمون Variance Inflation Factor یا همان عامل تورم واریانس رتبهبندی میشوند. آزمون VIF شدت همخطی میان متغیرهای مستقل را اندازهگیری میکند. به عبارت دیگر به چه میزان هر کدام از متغیرهای مستقل نسبت به متغیرهای مستقل دیگر، تحت تاثیر قرار گرفته است.
در آخر با بررسی همبستگی میان تمام متغیرها، دادههایی که از نظر ویژگی و درستی در محاسبه، عملکرد بهتری داشه باشند، بهعنوان مجموعه دادهها (Datasets) در اختیار سیستم قرار میگیرند.
پس از تشکیل مجموعه دادهها، فرایند وارد فاز سوم میشود (با توجه به تصویر شماره یک) و با توجه به دو مدل گروهبندی یا رگرسیونی، شروع به پیشبینی قیمت بیت کوین میکند. پس از اتمام، دادههایی که بهصورت خارج از کیسه، کنار گذاشته شده بودن، برای اینکه صحت و درستی برآورد را آزمایش کنند، در مدل بهکار گرفته میشوند. همانطور که در تصویر شماره یک مشاهده میکنید، در مدل رگرسیونی، خروجی در قالب یک نمودار و در مدل گروهبندی بهصورت افزایش یا کاهش، نمایش داده میشوند.
جمعبندی
در این مقاله سعی کردیم به توضیح یکی از الگوریتمهای پرطرفدار یادگیری ماشین، یعنی الگوریتم جنگل تصادفی یا رندوم فارست بپردازیم. جنگل تصادفی از مجموع چند درخت تصمیم تشکیل شده است. با استفاده از این الگوریتم، میتوان دادهها را به دو صورت دستهبندیشده یا رگرسیونی پیشبینی کرد. الگوریتم جنگل تصادفی در حوزههای مختلف مورد استفاده قرار میگیرد. از این الگوریتم در پیشبینی قیمت بیتکوین نیز استفاده میشود.










