
با افزایش تعاملات اقتصادی، اجتماعی و فرهنگی در چند دهه اخیر و در فضای اینترنت، تقاضا برای کپیبرداری از ویژگی تصادفی و غیرقابل پیشبینی بودن دنیای طبیعی هم بیشتر شد. اصطلاح «تصادفی بودن» یا «Randomness» یعنی وجود نداشتن الگو یا قابلیت پیشبینی در یک دنباله. نتایج پرتاب سکه، الگوی اثر انگشت و شکل دانههای برف نمونههای رایج این مفهوم هستند. اهمیت نتایج تصادفی در بلاکچین و وب ۳ بیش از سایر حوزههای دیجیتال است. قطعا معرفی کمیابی مصنوعی (Artificial Scarcity)، ایجاد مکانیسمهای امنیتی قوی و فرایند تصمیمگیری بیطرف و قابلاعتماد نیازمند ارائه نتایج غیرقابل پیشبینی است. با میهن بلاکچین همراه باشید تا مفهوم تصادفی، انواع آن و چالشهای تصادفی بودن در بلاکچین و اکوسیستم وب ۳ را برسی کنیم.
تولید اعداد تصادفی

الگوها و نتایج غیرقابل پیشبینی فراوانی را در طبیعت مییابیم، اما در مورد نتایج تصادفی رایانهها هم همانقدر مطمئن هستیم؟ رایانهها دستگاههای قطعی هستند و ممکن است تولید اعداد تصادفی واقعی از طریق مجموعهای از الگوریتمهای رایانهای امکانپذیر نباشد. بهعلاوه، گرچه رویدادهای تصادفی هر کدام بهطورجداگانه غیرقابل پیشبینی درنظرگرفته میشوند، اما تعداد و فراوانی نتایج مختلف در رویدادهای تکراری قابلپیشبینی است. به طور مثال نتیجه هر بار پرتاب تاس غیرقابل پیشبینی است. با این حال احتمال نتایج ۱۰۰ بار پرتاب تاس و بیش از آن را میتوان با اطمینان محاسبه کرد.
آیا نتایج تصادفی واقعا تصادفی هستند؟

برای اینکه بفهمیم ویژگی تصادفی واقعا تصادفی است یا خیر باید مجموعهای از اصول را برای یک دنباله تصادفی تعریف کنیم.
- غیرقابل پیشبینی: نتایج باید غیرقابل تشخیص باشند.
- بیطرفانه: شانس هر یک از نتایج باید به یک اندازه و برابر باشد.
- قابل اثبات: نتیجه باید به طور مستقل قابل تایید باشد.
- ضد دستکاری: فرایند تولید نتایج تصادفی باید در برابر هر گونه دستکاری ایمن باشد.
- غیرقابل تکرار: امکان بازتولید فرایند تولید نتایج تصادفی وجود ندارد، مگر اینکه توالی اصلی حفظ شود.
رایانه را میتوان یک دستگاه قابل پیشبینی دانست؛ زیرا اجزا و مدارهای از پیش تعیینشده و مجموعهای از کدها و الگوریتمهای تعریف شده امکان پیشبینی خروجی اعداد تصادفی یا دنباله تولیدشده توسط کامپیوتر در شرایط ثابت را بهوجود میآورد؛ درست همانطور که یک ماشین حساب نتیجه معادله ۲+۲ را عدد ۴ نشان میدهد، یک رایانه هم باید در ازای ورودی مشابه، یک خروجی مشخص تولید کند؛ بنابراین، ممکن است رایانهها قادر به تولید شرایط احتمال و اعداد تصادفی واقعی نباشند.
برای رفع این محدودیت، مولدهای اعداد تصادفی (RNG) از یک Seed استفاده میکنند. سید، مقدار شروع یا ورودی محاسبه است که برای تولید خروجی استفاده میشود. سید را میتوان بر اساس هر چیزی که بازتولید پیچدهای دارد تولید کرد. به طور مثال دادههای حاصل از یک عکس، زمان روز، حرکت ماوس کاربر را میتوان به عنوان سید استفاده کرد.
به هرحال، اگر بازتولید فرایند تولید اعداد تصادفی دشوار باشد، به این معنا نیست که بازتولید فرایند از نظر فنی غیرممکن است. اگر چندین روش تولید سید که تکرارپذیری سختی دارند با هم ترکیب شوند، نتایج نسبتا قابل اعتمادی تولید میکنند. حتی با این فرض که ممکن است درنهایت سیدها در طول زمان آشکار شوند، بازهم این روش قابل اعتماد است. اما در صورتی که برای تولید سید از یک روش ریاضی مشابه استفاده شود، آن وقت نتایج واقعا تصادفی نیستند. حالا ببینیم چه نوع «تصادفی بودن» را میتوانیم یک «تصادف واقعی» در نظر بگیریم؟
RNGهای شبه تصادفی در برابر RNGهای واقعی
به طور کلی میتوان مولدهای اعداد تصادفی (Random Number Generator) را به دو دسته تقسیم کرد؛ مولد اعداد تصادفی شبه تصادفی (Pseudo Random Number Generator) و مولد اعداد تصادفی واقعی (True Random Number Generator). مولد اعداد تصادفی شبه تصادفی برای تولید مقادیر تصادفی از الگوریتمهای ریاضی استفاده میکند و مولد اعداد تصادفی واقعی از ابزارهای فیزیکی مانند نویز اتمسفری کمک میگیرد.
عملکرد مولد اعداد تصادفی شبه تصادفی
مولد اعداد تصادفی شبه تصادفی (PRNG) مجموعهای از الگوریتمها هستند که با استفاده از فرمولهای ریاضی یک دنباله تصادفی را تولید میکنند. درواقع، این دنباله تصادفی تقلیدی از اعداد تصادفی واقعی است. از آنجایی که رایانهها سیستمهای متمایزی هستند، اعداد تولیدشده توسط آنها برای ناظران انسانی تصادفی بهنظر میرسد، اما ممکن است نتایج شامل الگوهای قابل تشخیص باشد و امکان شناسایی الگو از طریق تحلیلهای آماری گسترده وجود دارد.
عملکرد مولد اعداد تصادفی شبه تصادفی
مولدهای اعداد تصادفی واقعی (TRNG) برای تولید اعداد تصادفی بر مبنای پدیدههای طبیعی از منابع فیزیکی مانند نویز کیهانی، فروپاشی رادیو اکتیو ایزوتوپ یا ایستایی در امواج استفاده میکنند. از آنجایی که در این روش تصادفی بودن از پدیدههای فیزیکی استخراج میشود، ویژگی تصادفی بودن نسبت به رایانهها قویتر و غیرقابلپیشبینیتر است. در این حالت نیز امکان قطعی بودن اطلاعات استفادهشده در مولدهای اعداد تصادفی واقعی وجود دارد. در صورتی که کسی بتواند بین مولد اعداد تصادفی واقعی و پدیده مورد استفاده قرار بگیرد، میتواند همان سینگال را دریافت کند و دنباله اعداد را دقیقا بفهمد.
گرچه مولدهای اعداد تصادفی واقعی میتوانند دنبالههای تصادفی را تولید کنند که تقریبا فاقد الگوهای قابلتشخیص هستند و شانس شناسایی آنها کمتر است، اما به دلیل هزینه بالا استفاده از آنها برای کاربردهای رایج غیرعملی است. PRNGها در مقایسه با TRNGها مزیت دیگری به نام تکرارپذیری (Reproducibility) دارند. اگر ناظر فرایند نقطه شروع دنباله را بداند میتواند همان دنباله اعداد را بازتولید کند و به این ترتیب تایید فرایند تولید اعداد تصادفی نیز امکانپذیر میشود. این قابلیت یک ویژگی کارآمد و مفید برای اپلیکیشنهای نسل سوم وب است که از تصادفی بودن استفاده میکنند.
چرا تصادفی بودن در بلاکچین مهم است؟

مهمترین اصل رمزنگاری در بلاکچین، ایمن بودن فرایند تولید نتایج تصادفی است. تابع هش رمزنگاری یک عنصر ضروری در تولید کلید خصوصی کیفپول ارزهای دیجیتال هستند و دشواری حدس کلید خصوصی را تضمین میکنند. برخی بررسیها تعداد ترکیبهای کلید خصوصی ممکن در تابع هش SHA-۲۵۶ پروتکل بیت کوین را با تعداد تخمینی اتمها در جهان مشابه میدانند.
تصادفی بودن در الگوریتمهای اثبات کار
اساسا اجماع توزیعشده توسط تعداد پیامهایی که میتواند در یک دوره زمانی (توان عملیاتی) ارسال شود و مدت زمانی که طول میکشد تا یک پیام در سراسر شبکه ارسال شود (تأخیر) محدود میشود (Latency)، محدود میشود. از این رو، در یک بلاکچین که هزاران شرکتکننده توزیع شده باید به توافق برسند و هر نود باید پیام را به سایر نودها ارسال کند، اجماع توزیع شده عملینیست. بنابراین، شبکهای مانند بیت کوین از مکانیزم اثبات کار (PoW) استفاده میکند تا تعداد ارسال پیام لازم برای اجماع را محدود کند. الگوریتم اثبات کار به عنوان یک منبع تصادفی تعیین میکند که کدام بلاک به بلاکچین اضافه شود. از آنجایی که حل معمای محاسباتی ماینرها و رقابت آنها برای اضافه کردن یک بلاک به بلاکچین بسیار سخت و پیچیده است، احتمال اینکه چند نود به طور همزمان معما را حل کنند بسیار اندک است. به این ترتیب، تعداد پیامهای مورد نیاز شبکه برای رسیدن به اجماع محدود میشود.
تصادفی بودن در الگوریتمهای اثبات سهام
در سیستمهای گواه اثبات سهام (PoS) هم از تصادفی بودن به عنوان زیربنای توزیع منصفانه و غیرقابل پیشبینی مسئولیت اعتبارسنجها استفاده میشود. درصورتیکه یک عامل مخرب بتواند منبع تصادفی فرایند انتخاب را تحت تاثیر قرار دهد، به معنای آنست که میتواند شانس انتخاب شدن خودش را افزایش دهد و امنیت شبکه را به خطر بیندازد.
از آنجایی که بلاکچینها شفاف هستند تمام ورودیها و خروجیها در معرض مشارکتکنندگان قرار دارد و دنبالههای تولیدشده تصادفی را قابل پیشبینی میکند. به طور مثال برخی روشهای تولید اعداد تصادفی آنچین مانند رمزنگاری و هش بلاک دارای حفرههای امنیتی است که به راحتی قابل دستکاری هستند. اگر ماینر یا اعتبارسنج نتیجه خاص یک دنباله تصادفی را بخواهد، تولید کننده بلاک میتواند با تولید نکردن بلاکهایی که منفعتی برای او ندارند، بر روند تولید دنبالههای تصادفی اثر بگذارد. به زبان سادهتر میتواند پرتاب کردن تاس را تا رسیدن به نتیجه مطلوب ادامه دهد.
درحقیقت، راهحلهای مولد اعداد تصادفی خارج از زنجیره (Off-Chain) شفاف نیستند و کاربر مجبور است به ارائهدهندگان دادههای متمرکز و عدم دستکاری نتایج به نفع آنها اطمینان کند. بهعلاوه، کاربر هیچ راهی برای تشخیص تفاوت بین تصادفی واقعی و تصادفی دستکاری شده ندارد. با وجود اهمیت زیاد نتایج تصادفی در بلاکچین و وب ۳ هر دو راه حل تولید اعداد تصادفی آنچین و آفچین نگرانیهای خاص خودشان را دارند.
بررسی و اهمیت تصادفی بودن در وب ۳

ممکن است افراد بسیاری اهمیت نتایج تصادفی در بلاکچین و وب ۳ به ویژه در تعیین نتایج بازیهای بلاکچین، پروژههای NFT یا هنرهای دیجیتال را ندانند. اپلیکیشنهای وب ۳ برای ایجاد نتایج منصافانه و غیرقابل پیشبینی به یک منبع امن تصادفی نیاز دارند. بهطور مثال عملکردهایی مانند شناسایی مکان داراییهای درون بازیهای متاورس، افزودن تنوع به یک الگوریتم هنری مولد، تولید آیتمهای درون یک لوت باکس (Loot Box)، مینت توکنهای غیرمثلی (NFT)، توزیع جایزه بین برندهها، تایید اعتبار بلیط رویدادها یا تعیین دورهای مشارکتکنندههای سازمان خودگردان مستقل (DAO) برای یک نقش حاکمیتی خاص، همگی نیازمند منبع امن تصادفی هستند.
از آنجایی که این سیستمها مقدار قابل توجهی از ارزش دنیای واقعی را جمعآوری میکنند، نتایج بهدستآمده از راهحلهای تصادفی غیربهینه منجر به عدم تقارن اطلاعات و مزایای غیرمنصافانه برای زیرمجموعهای از شرکتکنندگان میشود. این سناریوها اغلب با ایجاد حلقه بازخورد منفی موجب عدم تعادل قدرت در تعاملات میشود. این پروسه در نهایت به شکست مکانیسمهای اقتصادی و نظریه بازی تسهیل فعالیتهای اقتصادی و همکاری اجتماعی میانجامد.
دسترسی به یک منبع تصادفی که ضد دستکاری و غیرقابل پیشبینی باشد و همه اعضا بتوانند آن را بازبینی (Audit) کنند، کار سادهای نیست. اما با این حال، بسیاری از پروتکلها و برنامههای موجود در صنعت وب ۳ به دلیل گرایش به عدالت و شفافیت از رقبای برجسته وب ۲ پیشیگرفتهاند. دسترسی به یک منبع تصادفی شفاف، بیطرف و قابل تایید کاربردهای جدیدی را در حوزههای متفاوت از قبیل بازیهای بلاکچینی، توکنهای بیهمتا (NFT)، حاکمیت غیرمتمرکز، رسانههای اجتماعی وب ۳، جذب سرمایه و امور خیریه، توکنهای اجتماعی و سایر موارد به وجود میآورد.
تابع تصادفی قابل تایید چین لینک (Chainlink VRF)
تا اینجا اهمیت نتایج تصادفی در بلاکچین و وب ۳ را بررسی کردیم. VRF چین لینک یک راهحل استاندارد صنعتی مولد اعداد تصادفی است. این راهحل چین لینک شرایطی را برای قراردادهای هوشمند (Smart Contaract) و سیستمهای آفچین به وجود میآورد تا با استفاده از رمزنگاری و محاسبات خارج از زنجیره به منبع تصادفی قابلتایید دسترسی داشته باشند. زمانی که توسط کلیدهای خصوصی از پیشتعیین شده نودهای اوراکل (Oracle) درخواستی صادر میشود و دادههای بلاک هنوز ناشناس هستند، VRF این اطلاعات را برای تولید یک عدد تصادفی و اثبات رمزنگاری ترکیب میکند. اپلیکیشن تنها در صورتی اعداد تصادفی ورودی را قبول میکند که دارای اثبات رمزنگاری معتبر باشند. اثبات رمزنگاری هم تنها در صورتی تولید میشود که تابع تصادفی قابلتایید ضد دستکاری باشد.
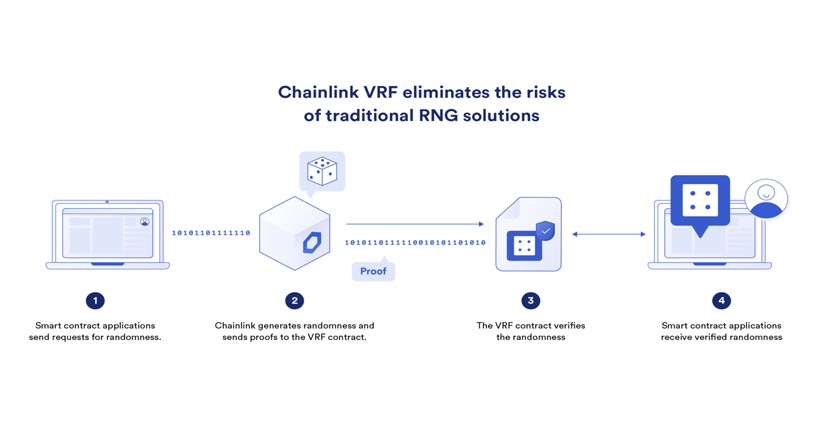
تابع تصادفی قابل تایید چین لینک از زمان لانچ بیش از ۶.۵ میلیون درخواست برای اعداد تصادفی منصفانه و بیطرف را انجام داده است. VRF چین لینک در حال حاضر اعداد تصادفی قابل تایید را به بیش از ۳۴۰۰ قرارداد هوشمند در شبکه بلاکچینهای متعدد از جمله؛ آوالانچ (Avalanche)، زنجیره بیانبی (BNB Chain) اتریوم (Ethereum) و پالیگان (Polygon) ارائهمیدهد.
ویژگیهای استاندارد Chainlink VRF
- غیرقابلپیشبینی بودن نتایج تصادفی: پیشبینی نتایج تصادفی تابع تصادفی قابل تایید چین لینک برای هیچکس امکانپذیر نیست. زیرا دادههای بلاک در زمان درخواست تصادفی ناشناخته هستند.
- منصفانه و بیطرف بودن نتایج: اعداد تصادفی تولیدشده توزیع یکنواختی دارند. به عبارت دیگر، شانس انتخاب همه اعداد مساوی است.
- قابل تایید بودن نتایج: کاربران میتوانند با استناد به ورودیهای تصادفی VRF چین لینک از طریق تایید آنچین اثبات رمزنگاری، یکپارچگی اپلیکیشن را تایید کنند.
- ضد دستکاری بودن فرایند: اوراکل، نهادهای بیرونی، تیم توسعه و هیچ کس دیگری نمیتواند فرایند تولید اعداد تصادفی را دستکاری کند. در صورتی که فرایند VRF دستکاری شود، نود نمیتواند یک اثبات رمزنگاری معتبر را تولید کند و قرارداد هوشمند هم ورودی اعداد تصادفی را قبول نمیکند.
- شفافیت: به دلیل اینکه کدها دارای منبع باز هستند کاربران میتوانند فرایند تصادفی بودن را اعتبار سنجی کنند.

به لطف این ویژگیهای بینظیر اپلیکیشنهای مبتنی بر Chainlink VRF میتوانند از طریق مولد اعداد تصادفی ضد دستکاری، نتایج منصافانه و غیرقابل پیشبینی را تولید کنند. به این ترتیب، تجارب و ویژگیهای جذابی امکانپذیر میشود.
جمعبندی
همانطور که تصادفی بودن (Randomness) در طبیعت و دنیای فیزیک کاربردهای زیادی دارد، در دنیای دیجیتال و فضای بلاکچین نیز نیازمند نتایج تصادفی هستیم. اما نکته اینجاست که چطور باید به نتایج تصادفی رایانهای اعتماد کنیم؟ نتایج تصادفی باید غیرقابل پیشبینی، بیطرف، قابل اثبات، ضد دستکاری و غیرقابل تکرار باشند. اهمیت نتایج تصادفی در بلاکچین و وب ۳ به دلایل تنوع کاربردهایی از قبیل بازیهای بلاکچینی، پروژههای NFT، حاکمیت غیرمتمرکز در دائو، رسانههای اجتماعی وب ۳ و غیره دوچندان میشود. به نظر شما تصادفی بودن در فضای بلاکچین و وب ۳ چقدر اهمیت دارد؟ آیا نتایج بازیها، داراییهای کمیاب، نقشهای حاکمیت در سازمانهای خودگردان در دائو چقدر تحت تاثیر نتایج تصادفی است؟ آیا احتمال دستکاری نتایج تصادفی در قراردادهای هوشمند وجود دارد؟












