در بازارهای پیشبینی، جواب طولانی همیشه جواب بهتر نیست. کاربری که روی نتیجه یک مسابقه، روند بازار یا سناریوی بعدی تصمیم میگیرد، دنبال این نیست که مدل هوش مصنوعی چقدر با اعتمادبهنفس حرف میزند. مسئله اصلی این است: کدام مدل زودتر مسیر درست را میبیند و کدام مدل تحلیلی مرتب تحویل میدهد؟
گزارش پیشبینی ۶ مدل هوش مصنوعی شامل ChatGPT، Grok، Qwen، DeepSeek، Gemini و Claude برای چند مسابقه مرحله حذفی جام جهانی و مقایسه آن با نتایج واقعی، برای کاربران کریپتو هم بیربط نیست، چون استفاده از هوش مصنوعی در بازارهای پیشبینی، تحلیل خبر، ساخت سناریو و حتی ترید ارز دیجیتال با هوش مصنوعی هر روز جدیتر میشود. اما همین گزارش نشان میدهد مدلها همیشه در یک کار خاص خوب عمل نمیکننپ.
تا اینجای مرحله حذفی، کانادا با نتیجه ۱ بر ۰ آفریقای جنوبی را شکست داد، برزیل ۲ بر ۱ ژاپن را برد، آلمان در ضربات پنالتی مقابل پاراگوئه حذف شد و هلند هم پس از تساوی ۱ بر ۱، در پنالتیها به مراکش باخت. بازی بلژیک و سنگال هم با تساوی ۲ بر ۲ و بازگشت در وقت اضافه، دوباره نشان داد مرحله حذفی چقدر میتواند پیشبینیها را خراب کند. دقیقاً همان جایی که مدلهای هوش مصنوعی، با تمام ظاهر تحلیلیشان، شروع میکنند به لو دادن محدودیتهایشان. چه سورپرایزی؛ ماشینها هم وقتی توپ گرد میشود، گاهی مثل انسانها اشتباه میکنند.
DeepSeek و Gemini؛ موفق در دیدن سناریوی مراکش
مهمترین بخش این مقایسه به پیشبینی بازی هلند و مراکش برمیگردد. روی کاغذ، هلند تیم قویتری بود. ترکیب بهتر، عمق بیشتر و سابقه قابلاعتمادتر باعث میشد بیشتر مدلها در نهایت هلند را تیم صعودکننده بدانند. بعضی مدلها سختی بازی را تشخیص دادند، اما در انتخاب برنده همچنان به تیم محبوبتر تکیه کردند.

اینجا DeepSeek و Gemini متفاوت عمل کردند. Gemini فقط نگفت بازی نزدیک میشود؛ سناریوی دقیقتری داد: تساوی ۱ بر ۱ در وقت قانونی و برد مراکش در ضربات پنالتی. نتیجه واقعی هم همین مسیر را رفت. بازی ۱ بر ۱ شد و مراکش در پنالتیها ۳ بر ۲ هلند را حذف کرد.
DeepSeek هم فاصله زیادی با نتیجه نداشت. این مدل احتمال تساوی ۱ بر ۱ یا ۰ بر ۰ در وقت قانونی را مطرح کرد، از کشیده شدن بازی به وقت اضافه یا پنالتی گفت و در نهایت به صعود مراکش از مسیر دفاع و ضدحمله متمایل شد.
این بخش برای کاربران بازارهای پیشبینی مهم است. چون در چنین بازارهایی، فقط دانستن اینکه «بازی نزدیک است» کافی نیست. مدل باید بتواند بین «بازی نزدیک ولی صعود تیم محبوب» و «بازی نزدیک با احتمال حذف تیم محبوب» فرق بگذارد. در این نمونه، DeepSeek و Gemini این تفاوت را بهتر دیدند. برای مطالعه بیشتر درباره جایگاه DeepSeek در رقابت مدلهای هوش مصنوعی، گزارش میهن بلاکچین درباره دیپسیک و آینده رقابت با OpenAI هم میتواند لینک داخلی مناسبی باشد.
Grok و Qwen؛ بهتر در پیشبینی بردهای نزدیک تیمهای مدعی
در کنار عملکرد DeepSeek و Gemini در بازی مراکش، Grok و Qwen هم در چند مسابقه دیگر خروجی دقیقی داشتند. نقطه قوت آنها بیشتر در بازیهایی دیده شد که برنده احتمالی تا حدی مشخص بود، اما اختلاف نتیجه نه.
در بازی آفریقای جنوبی و کانادا، بیشتر مدلها کانادا را شانس اصلی پیروزی میدانستند. مسئله این بود که آیا کانادا برد راحتی خواهد داشت یا نه. Grok برد ۱ بر ۰ کانادا را پیشبینی کرد و Qwen هم به برد با اختلاف یک گل نزدیک شد. نتیجه واقعی همان برد حداقلی بود.
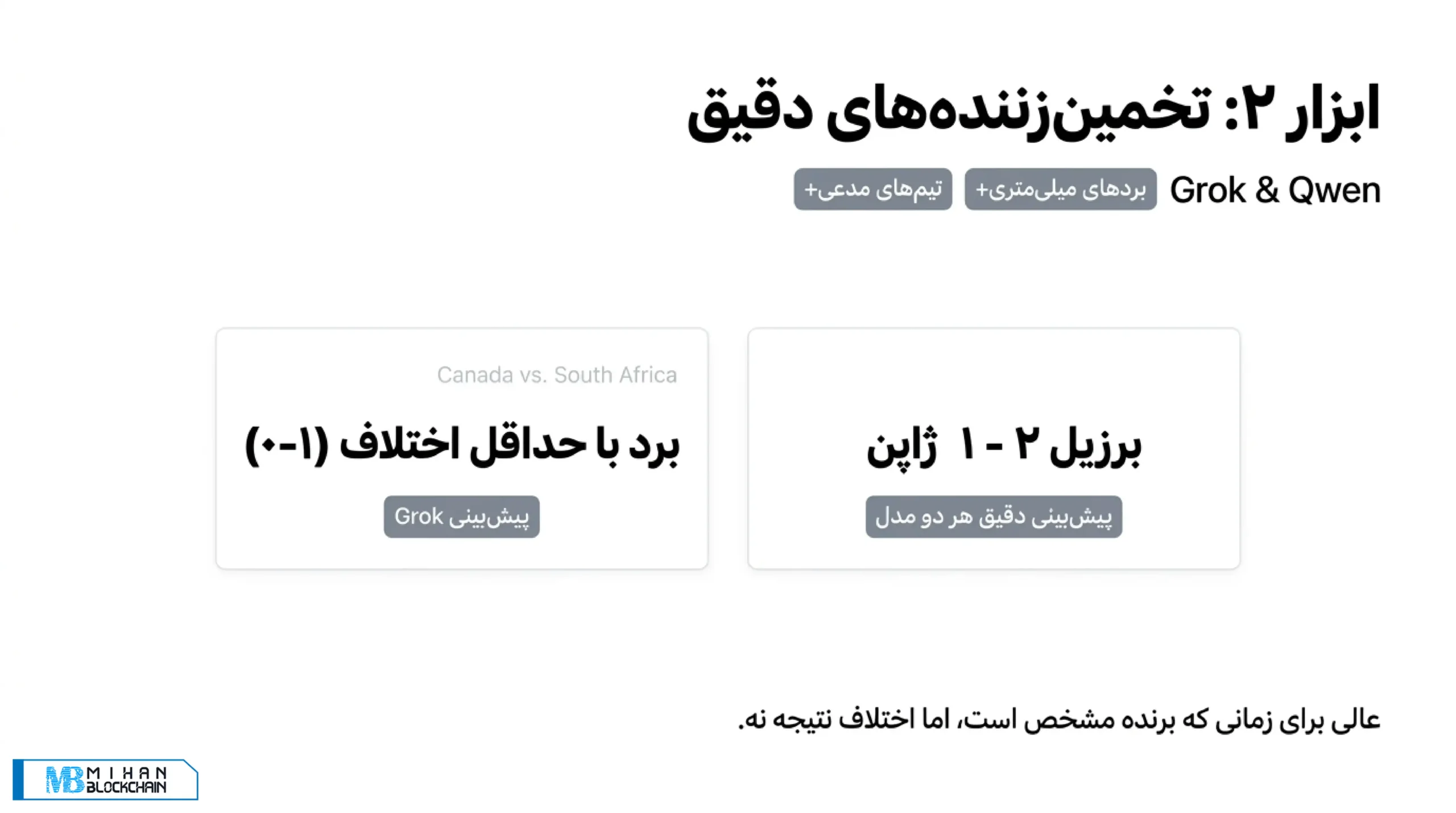
در بازی برزیل و ژاپن هم وضعیت مشابهی دیده شد. بیشتر مدلها برزیل را تیم برتر میدانستند، اما سؤال اصلی این بود که ژاپن تا چه اندازه میتواند بازی را سخت کند. Grok و Qwen هر دو نتیجه ۲ بر ۱ به سود برزیل را پیشبینی کردند و بازی هم دقیقاً با همین نتیجه تمام شد.
در مسابقه ساحل عاج و نروژ نیز هر دو مدل دوباره به نتیجه ۲ بر ۱ برای نروژ رسیدند. پیشبینی برد نروژ با حضور ارلینگ هالند چندان عجیب نبود، اما تشخیص اینکه ساحل عاج با قدرت بدنی و حمله از کنارهها اجازه یک بازی یکطرفه را نمیدهد، بخش مهمتری از تحلیل بود.
در این نمونهها، Grok و Qwen بیشتر شبیه مدلهایی بودند که در سناریوهای کمریسکتر، اختلاف نتیجه را بهتر تخمین میزنند. آنها لزوماً بهترین گزینه برای پیدا کردن شگفتیهای بزرگ نبودند، اما در تشخیص اینکه یک تیم مدعی با اختلاف کم میبرد یا بازی را راحتتر جمع میکند، عملکرد قابلتوجهی داشتند.
برای لینکدهی داخلی، هنگام اشاره به Grok میتوان به مقاله میهن بلاکچین درباره استفاده از هوش مصنوعی گروک در ترید ارزهای دیجیتال لینک داد. این لینک از نظر موضوعی به بحث استفاده عملی از مدلهای هوش مصنوعی برای تصمیمگیری نزدیک است.
ChatGPT؛ تحلیل خوب از روند بازی، اما نه همیشه قاطع در نتیجه
ChatGPT در این مقایسه کمتر از Gemini در پیشبینی شگفتیها درخشید و مثل Grok و Qwen هم چند نتیجه دقیق پشت سر هم نداد. با این حال، نقطه قوتش جای دیگری بود: توضیح روند احتمالی بازی.
برای مثال، در بازی برزیل و ژاپن، ChatGPT صعود برزیل را پیشبینی کرد، اما برد آسانی برای آن نساخت. این مدل به پرسینگ، دوندگی و نظم ژاپن اشاره کرد و احتمال داد ژاپن بتواند برزیل را تحت فشار بگذارد، حتی شاید گل اول یا گل مساوی را بزند. در بازی ساحل عاج و نروژ هم ChatGPT برد نروژ را محتمل دانست، اما از فیزیک بدنی، حملات کناری و انتقال سریع توپ توسط ساحل عاج بهعنوان عوامل دردسرساز نام برد.

در بازی انگلیس و جمهوری دموکراتیک کنگو نیز ChatGPT صرفاً سراغ برد پرگل انگلیس نرفت. این مدل احتمال داد کنگو با دفاع فشرده سرعت بازی را بگیرد و کار را برای انگلیس سخت کند. انگلیس در نهایت صعود کرد، اما نه با بردی راحت.
این یعنی ChatGPT برای فهمیدن «چرا ممکن است بازی سخت شود» کاربرد دارد، اما همیشه برای انتخاب نتیجه نهایی قاطع نیست. این نکته در کریپتو هم آشناست. در بسیاری از سناریوهای تحلیلی، ChatGPT میتواند دادهها، خبرها و ریسکها را مرتب کند، اما خروجی آن نباید مستقیم بهعنوان سیگنال نهایی استفاده شود. مقاله میهن بلاکچین درباره تبدیل اخبار ارز دیجیتال به سیگنال معاملاتی با ChatGPT دقیقاً از همین زاویه میتواند لینک داخلی خوبی باشد: استفاده از مدل، همراه با راستیآزمایی انسانی.
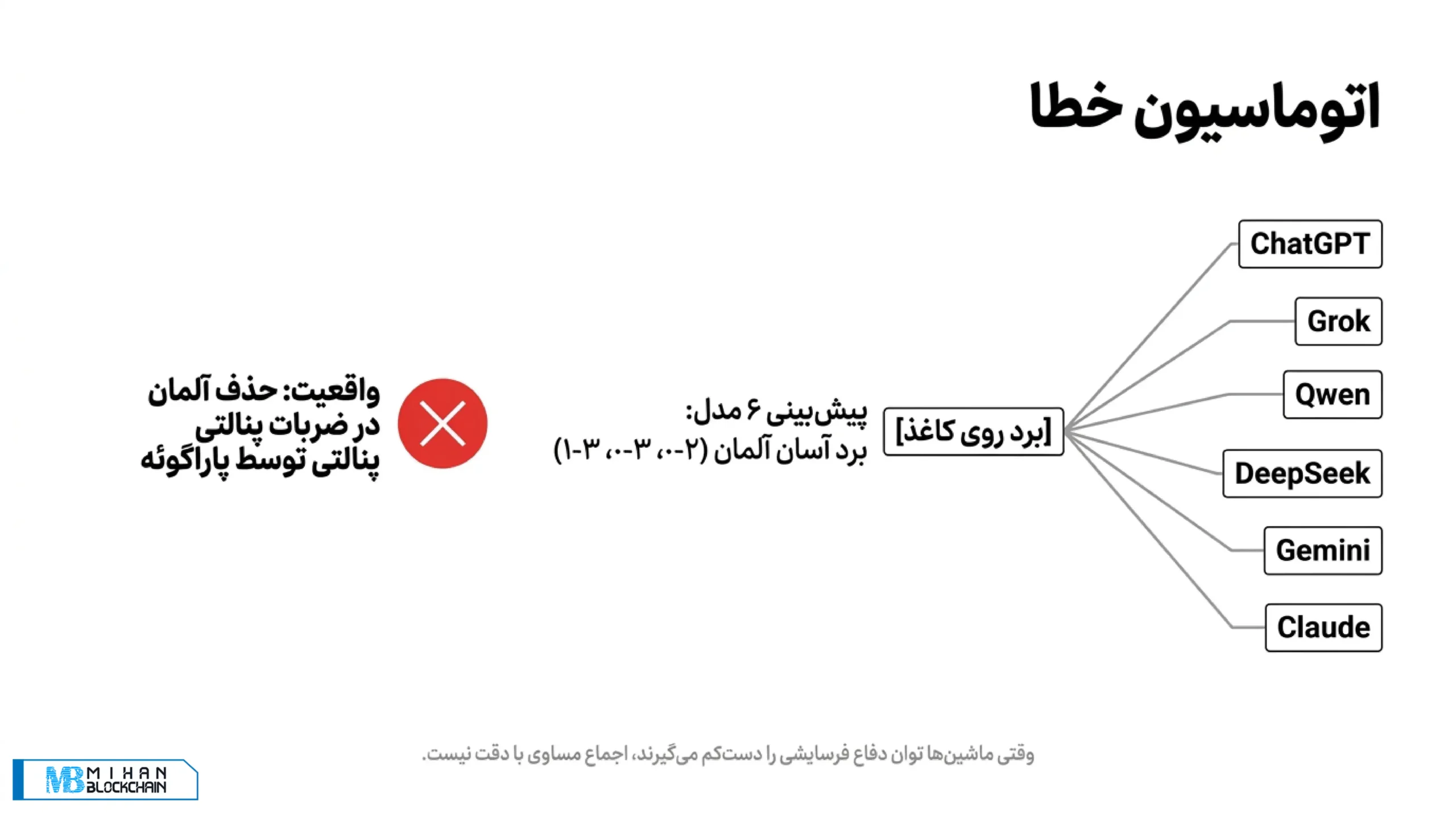
حذف آلمان؛ جایی که همه مدلها اشتباه کردند
اگر بازیهای قبلی نقاط قوت مدلها را نشان دادند، بازی آلمان و پاراگوئه نقطه ضعف مشترک آنها بود. تقریباً همه مدلها، از ChatGPT و Grok گرفته تا Qwen، Gemini و Claude، آلمان را برنده دانستند. بیشتر پیشبینیها هم به نتایجی مثل ۲ بر ۰، ۳ بر ۰ یا ۳ بر ۱ به سود آلمان نزدیک بود.
دلیل تحلیلها هم روشن بود: آلمان روی کاغذ بازیکنان بهتر، عمق ترکیب بیشتر و قدرت هجومی بالاتری داشت. اما همین تکیه روی برتری کاغذی باعث شد مدلها توان پاراگوئه در کند کردن بازی، دفاع فرسایشی و کشاندن مسابقه به پنالتی را دستکم بگیرند.
آلمان نه در وقت قانونی کار را تمام کرد، نه در وقت اضافه. در نهایت هم در ضربات پنالتی حذف شد. این نمونه نشان میدهد حتی وقتی همه مدلها با هم همنظرند، اجماع آنها لزوماً به معنی بالا رفتن احتمال صحت پیشبینی نیست. گاهی فقط همه با هم یک اشتباه تمیز و منظم انجام میدهند. چه منظره باشکوهی از اتوماسیون خطا.
Claude؛ تحلیلگر محتاط، نه شکارچی شگفتی
Claude در این مقایسه رفتاری نزدیک به ChatGPT داشت. تحلیلهایش منظم و نسبتاً کامل بود، اما در بازیهایی که نیاز به انتخاب خلاف جهت بازار داشت، محافظهکارتر عمل کرد. در بازی هلند و مراکش، Claude هم مثل ChatGPT خطر وقت اضافه و پنالتی را دید، اما در نهایت به صعود هلند متمایل شد.
این نوع خروجی برای کاربری که میخواهد روند بازی، نقاط مقاومت و سناریوهای محتمل را بفهمد مفید است. اما برای کاربری که دنبال تشخیص یک آپست مشخص است، کافی نیست. لینک داخلی پیشنهادی در اولین اشاره به Claude میتواند مقاله میهن بلاکچین درباره معرفی هوش مصنوعی Claude 2 باشد.
کدام مدل دقیقتر بود؟
براساس همین چند مسابقه، نمیتوان رتبهبندی قطعی ساخت. تعداد نمونهها کم است و مسابقات فوتبال هم بهخصوص در مرحله حذفی، با پنالتی، اخراج، مصدومیت و جزئیات کوچک تغییر میکنند. اما تفاوت سبک مدلها قابلمشاهده است.
DeepSeek و Gemini در تشخیص شگفتیها بهتر ظاهر شدند، بهخصوص در بازی هلند و مراکش. Gemini حتی مسیر بازی را با تساوی ۱ بر ۱ و برد مراکش در پنالتیها درست پیشبینی کرد. هنگام اشاره به Gemini، لینک داخلی مناسب میتواند گزارش میهن بلاکچین درباره جمینای ۲.۵ پرو گوگل باشد.
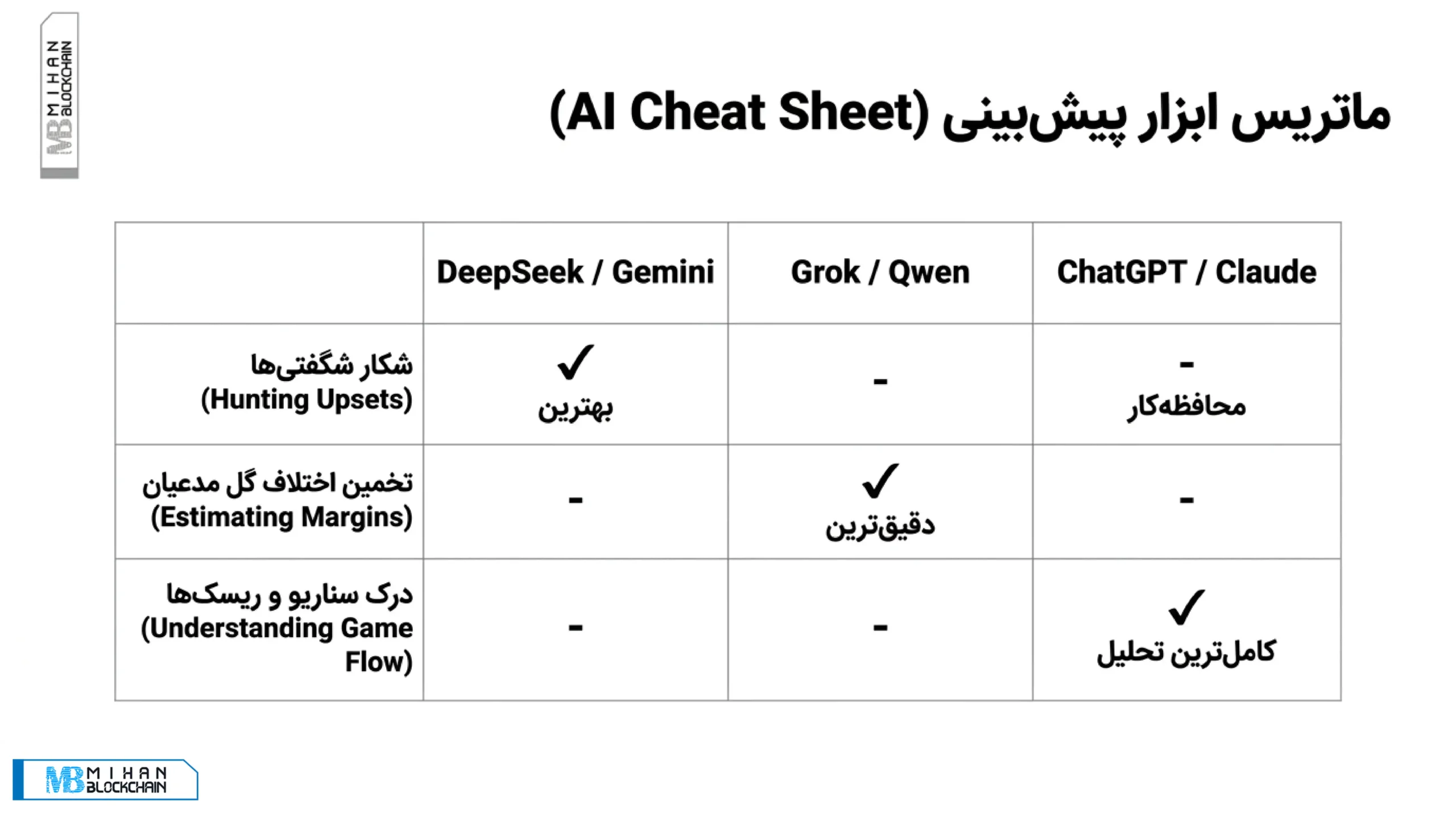
Grok و Qwen در بازیهایی که تیم برتر مشخصتر بود، عملکرد خوبی در تشخیص نتیجه نزدیک داشتند. کانادا، برزیل و نروژ نمونههای اصلی این بخش بودند.
ChatGPT و Claude بیشتر برای تحلیل روند بازی مفید بودند. آنها میتوانستند بگویند کدام تیم قرار است کار را سخت کند، کجا ممکن است بازی قفل شود و چرا برد تیم محبوب لزوماً راحت نیست. اما در انتخاب شگفتیها، محافظهکارتر بودند.
نتیجه عملی این است: سؤال درست این نیست که «کدام مدل فوتبال را بهتر میفهمد؟» سؤال بهتر این است که «برای چه کاری از کدام مدل استفاده کنیم؟»
اگر هدف پیدا کردن سناریوهای غیرمنتظره باشد، DeepSeek و Gemini در این نمونهها خروجی جسورانهتری داشتند. اگر هدف تخمین نتیجه بازیهایی باشد که یک تیم از قبل مدعیتر است، Grok و Qwen بهتر ظاهر شدند. اگر هدف فهمیدن روند بازی، مقاومت تیم ضعیفتر و نقاط ریسک باشد، ChatGPT و Claude ابزارهای بهتری هستند.
برای کاربران بازارهای پیشبینی و حتی معاملهگران کریپتو، پیام گزارش ساده است: مدل هوش مصنوعی را نباید مثل گوی پیشگویی دید. بهتر است خروجی چند مدل کنار هم گذاشته شود، نوع خطای هر مدل شناخته شود و تصمیم نهایی با بررسی داده، زمینه و ریسک گرفته شود. در غیر این صورت، فقط یک متن قانعکنندهتر برای اشتباه کردن داریم؛ نسخهای مدرنتر از همان عادت قدیمی انسانها.